Einleitung
Achtung
diese Seite ist überholt! Ich benutze inzwischen einen anderen
Algorithmus. Diese Seite hat daher nur noch historischen Wert!
Ich beschreibe hier
einen Rendering-Algorithmus, den ich entwickelt habe - oder besser
gesagt: den ich mit der Zeit immer weiter ausgebaut habe. "Rendering"
meint hier das Erzeugen eines (zweidimensionalen) Bildes, das eine
dreidimensionale Szene zeigt. Dieser Algorithmus ist nicht gerade das
Non-Plus-Ultra auf dem Gebiet. Da ich aber schon einige
Male danach gefragt wurde, wie, bzw. mit welchem Programm denn die Fraktal-
oder auch Bezier-Bilder auf meinen
Seiten entstanden sind und ich eine "Doku" in dieser Form auch für
mich selbst immer hilfreich finde, habe ich mich mal an die
Beschreibung gemacht. Dienen soll es (neben mir selbst, wenn ich mich
mal wieder frage, wie ich dieses oder jenes eigentlich gemacht habe)
Leuten, die wie ich, "mal eben" 3D-Objekte selbst visualisieren wollen.
Hier sind neben einem relativ einfachen Ansatz auch einige Fallen
erwähnt, an denen ich lange herumgeknobelt habe. Wer bestimmte
Nachteile vermeiden will, die "mein" Ansatz prinzipiell mit sich
herumschleppt, wird diese hier auch beschrieben finden. Man kann sich
dann überlegen, ob man diese nicht besser von Anfang an vermeiden
möchte...
Generelle Merkmale
Der im Folgenden erläuterte Algorithmus zeichnet sich
durch folgende Features und Nicht-Features aus:
- Im Vergleich zu
dem was Echtzeitbibliotheken (z.B. das von mir auch eingesetzte Java3D)
so zu leisten im Stande, sind ist mein Renderingalgorithmus furchtbar laaaaangsaaaaam.
- Dafür
berechnet er den Schattenwurf,
was sehr zum räumlichen Eindruck
der Darstellung beiträgt (das kann Java3D z.B. nicht :-).
- Schatten werden
jedoch nur von sichtbaren
Objekten / Objektteilen geworfen (dazu
später mehr). Im Beispiel unten links ist der Effekt gut zu sehen:
Das Licht scheint von oben rechts durch den blauen Zylinder hindurch,
weil die Rückwand des Zylinders verdeckt und damit für den
Algorithmus nicht vorhanden ist. Unten rechts tritt das Problem nicht
mehr auf, weil der Zylinder oben geschlossen ist (rote Kappe).
 |
|
 |
(Falscher)
Schattenwurf
|
|
(Korrekter)
Schattenwurf
|
- Zudem ist derzeit
auch nur eine Lichtquelle
vorgesehen, die ihre "Lichtstrahlen" parallel
auf die Szenerie wirft - also quasi eine unendlich weit entfernte
Lichquelle. Dass es nur eine Lichtquelle gibt ist aber keine
prinzipielle Einschränkung, jedoch
würden weitere Lichquellen entsprechend mehr Rechenzeit erfordern
(für zwei Lichtquellen verdoppelt sich der Rechenaufwand
annähernd...).
- Für das
Rendern von Fraktalen hat der Ansatz den Vorteil, dass er direkt auf (Raum-)Pixeln
(manchmal auch "Voxel" genannt) arbeitet (ein Raumpixel ist durch
seine X- und Y- und zusätzlich durch seine Z-Koordinate bestimmt).
Eine Umrechnung in irgendeine
Art von Flächen (z.B. Dreiecksflächen) wird nicht
benötigt. Umgekehrt müssen Objekte die sich z.B. aus
Bezier-Flächen zusammensetzen
auch erst in eine Menge von Raumpixeln überführt werden. Ein
Nachteil,
insbesondere auch für perspektivische Darstellungen ist, dass so
eine
Repräsentation durch Raumpixel nicht mehr so ohne weiteres
(größer)
skalierbar ist (man kennt den Effekt von normalen 2D pixelbasierten
Grafikformaten, wie Jpeg, PNG, Gif, Tiff, BMP usw. - im Gegensatz zu
vektororientierten Formaten, wie z.B. SVG, die ohne Einbußen
beliebig
vekleinerbar und
vergrößerbar sind).
- Auch die
Perspektive ist eine sogenannte "Parallelperspektive"
(man
kennt
das
evtl.
noch
aus
dem
Kunstunterricht).
Das
hat
unter
anderem
zur
Folge,
dass
die
Größe
in
der
ein
Objekt
/
Objektteil
dargestellt
wird
nicht
von
der
Entfernung
zum
Betrachter
abhängt.
Ich
verwende
den
Begriff
"Sichtebene"
für
eine
angenommene
Projektionsfläche auf der schließlich das
gerenderte 2D-Abbild der Szene entsteht. Da die Abbildung mit
parallelen "Strahlen" erfolgt, ist es vollkommen egal, an welcher
Z-Position dieses Sichtebene angenommen wird (es findet dadurch keine
Größenveränderung des projezierten Abbilds statt).
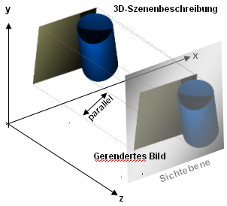 |
|
Parallelperspektivische
Abbildung:
Die 3-dimensionale Szene wird mit
parallelen "Strahlen" auf eine
"Sichtebene" geworfen um ein 2-dimensionales Abbild zu erhalten
|
- Eine
Möglichkeit einer "perspektivischen Verzerrung", um den Eindruck
einer "Fluchpunktperspektive"
zu erzeugen, ist inzwischen auch
eingebaut, ist aber mehr ein Trick und hat gewisse Nachteile.
Zudem ist dies eine Vorverarbeitung,
bzw.
gehört
zu
der
Art
und
Weise
wie
man
die
Daten
erzeugt,
die
dann
dem
Renderer
zum
"Fraß"
vorgeworfen
werden
-
es wird nämlich praktisch das
Objekt selbst und nicht nur die Perspektive "verzerrt". Diese Variante
hat einige
(unerwünschte) Auswirkungen
auf Schatten, Reflektionen und Spiegelungen. Unten sind die normale
Parallelperspektive, die hier verwendete Art der Fluchtpunktperspektive
und zum Vergleich, ein ähnliches, mit Java3D gerendertes Bild zu
sehen. Zu erkennen ist, dass die Verzerrungen soweit richtig aussehen,
jedoch sind die Schatten, trotz gleichen Lichteinfallswinkels,
gegenüber der parallelperspktivischen Darstellung verändert
(leider kann ja Java3D keine Schatten, so dass man es damit nicht
vergleichen kann).
 |
|
 |
|
 |
Parallelperspektive
|
|
Fluchtpunktperpektive
(gleicher
Lichteinfallswinkel
wie
links)
|
|
Zum Vergleich:
ähnliche Perspektive mit Java3D
|
Dass schon die Szenenbeschreibung selbst verzerrt erstellt wird und
nicht erst die Abbildung der Szene, hat zwei wesentliche Gründe:
- den oben
bereits angedeuteten
Grund, dass eine einmal erstellte Szenenbeschreibung aus "Raumpixeln"
nicht ohne Qualitätseinußen vergrößerbar ist.
Durch die perspektivische Verzerrung erscheinen aber Teile der Szene
größer (im Beispiel oben ist z.B. die Öffnung des
Zylinders deutlich größer als in der Parallelperspektive,
obwohl das Bild insgesamt etwa die gleiche Größe hat).
- werden, in
einer perspektivischen Darstellung, Objekte und Objektteile sichtbar,
die in einer Parallelperspektive überhauptnicht sichtbar sind.
Wie schon beim Schattenwurf erwähnt und wie später noch
genauer erläutert wird, werden aber zur Zeit
nur sichtbare Teile in die Beschreibung der Szene aufgenommen. Unten
ist ein Beispiel dafür zu sehen - die Innenseiten der beiden
Säulen sind nur in der Fluchtpunktperpektive sichtbar,
während man in der Parallelperspektive nur die Vorderseiten sieht.
 |
|
 |
|
 |
Parallelperspektive
(nur die Vorderseiten der Säulen sind sichtbar)
|
|
Fluchtpunktperpektive
(die Innenseiten der Säulen sind sichtbar)
|
|
Nochmal eine
ähnliche Perspektive mit Java3D
|
- Wie aus der Fotografie bekannt, trägt auch die Tiefenschärfe, bzw. oft eher
der
Mangel an Tiefenschärfe, sehr zum räumlichen Eindruck bei.
Die Schärfe eines Punktes
ist dabei abhängig davon, wie weit der
Punkt von einer zu definierenden "Schärfeebene" entfernt ist. Bei
mir wird zu diesem Zweck auf jeden Punkt ein Gausscher Weichzeichner
mit
entsprechend angepasstem Radius angewendet. Allerdings ist die
Berechnung dafür sehr langsam, da
ja jeder (nicht scharfe) Punkt über einen umliegenden Bereich
von Nachbarpunkten "verschmiert" werden muss. Meine derzeitige
Implementierung verbrät
darüber hinaus viel Speicher, aber da gäbe es noch
Einsparpotenziale. Das Beispiel unten zeigt
Bilder mit unterschiedlicher
Tiefenschärfe, wobei die Objekte zusätzlich mit einer Textur
überzogen wurden, um den Effekt noch deutlicher zu machen:
 |
|
 |
|
 |
Bild mit
geringer Tiefenschärfe
|
|
Bild mit
mittlerer Tiefenschärfe |
|
Zum Vergleich
dasselbe Bild ohne Unschärfen
|
- Eine Blauverschiebung
und Dunst können
hinzugefügt werden. Der Dunst ist dabei ein tiefenabhängiges
Aufhellen (Weißverschiebung). Bei der Blauverscheibung werden
Teile von Rot und Grün zu Blau - je weiter ein Punkt weg ist desto
stärker.
 |
|
 |
Zusätzlich
zur
Tiefenunschärfe
ist
hier
eine
tiefenabhängige
Weiß-
und
Blauverschiebung
benutzt
worden
|
|
...und das
Ganze nochmal mit Hintegrund (aber weniger Unschärfe, Blau- und
Weißverschiebung)
|
- Texturen sind
übrigens nicht Teil des Renderings und werden daher hier nicht
weiter
erläutert. Da aber für jedes Pixel eine eigene Farbe bestimmt
werden kann, können natürlich prinzipiell auch Texturen
über ein Objekt gelegt werden. Wie das passiert liegt aber
vollständig in der Hand der die Szenenbeschreibung erstellenden
Funktionen und hat mit dem eigentlichen Rendering daher nichts zu tun.
- Spiegelungen
können ebenfalls berechnet werden, allerdings werden nur Bilder
gespiegelt,
die sich z.B. auf den sechs Seiten einer die Szene virtuell umgebenden
Box befinden (andere Formen, wie Kugeln, Zylinder, etc. sind auch
denkbar). Spiegelungen der Objekte untereinander sind nicht
möglich. Damit wird bei der Spiegelung auch nicht
berücksichtigt, dass ein zu spiegelndes Bild evtl. durch ein
anderes Objekt verdeckt ist und somit eigentlich dieses Objekt zu
spiegeln wäre. Die Spiegelung ist bei mir ein
Vorverarbeitungsschritt, bei dem die Farbe eines Objektpunktes
entsprechend angepasst wird und damit eigentlich auch nicht Teil des
Renderings.
 |
|
 |
Drei Seiten
einer ein
Objekt umgebenden "Spiegelungs-Box"
|
|
Gerendertes
Objekt
mit
Spiegelungen
|
Generell würde ich
heute einiges anders machen. Man muss aber berücksichtigen, dass
ich eigentlich ja "nur mal schnell" meine 3D-Fraktale irgendwie nicht
nur
berechnen, sondern auch ansehen können wollte. Da war zwar schnell
was hingeschlunzt, aber so richtig befriedigend war das dann noch nicht
...also
weitergetüftelt. So kam dann am Ende der hier beschriebene
Algorithmus raus, der eben noch einige "Erbkrankheiten" mit sich
herumschleppt.
Richtig "chic", aber auch um einiges aufwändiger, wäre
natürlich ein "echter" Ray-Tracer
gewesen. Beim Ray-Tracing
werden, wie der Name schon andeutet, der Weg virtueller Lichtstrahlen,
zwischen den Lichtquellen und dem virtuellen Auge verfolgt, womit
prinzipiell beliebige Spiegelungen, Schattenwürfe, etc.
berechenbar sind (aus Effizienzgründen werden allerdings
normalwerweise einige
Einschränkungen gemacht)1). Zum
Thema Ray-Tracing kann aber an
anderer Stelle mehr nachgelesen werden.
Szenen- /
Objektbeschreibung
Generell arbeitet der
Algorithmus mit drei bzw. vier Matritzen, deren Höhe (Anzahl der
Werte in
X-Richtung) und Breite (Anzahl der Werte in Y-Richtung) der Höhe
und Breite des zu erstellenden Bildes entspricht2):
- Die erste Matrix ist der
sogenannte Z-Buffer, der
für jedes Pixel die Entfernung zum Betrachter enthält.
Genauer muss man von der Entfernung zur Sichtebene sprechen. Die
Sichtebene wird dabei, der Einfachheit halber, an Position z=0
angenommen. Die Beschränkung auf einen
Z-Wert für jedes Element dieser Matrix hat mehrere Nachteile - so
ist es damit z.B. nicht möglich mehrere teiltransparente Ebenen
darzustellen. Es ist also nicht möglich, dass man hinter einer
Oberfläche noch weitere
Objekt(-teile) durchschimmern sieht. Außerdem liegt hier der
Grund für die oben schon kurz erwähnte Einschränkung,
dass nur sichtbare Objektteile Schatten werfen können, denn von
anderen Objekteilen verdeckte Bereiche sind in dem zugrundeliegendem
Z-Buffer schlicht nicht repräsentiert. In Wirklichkeit werfen
natürlich auch verdeckte Objekte (sichtbare) Schatten. Man stelle
sich einen Reihe von seitlich beleuchteten Säulen vor, wobei man
nur die vorderste Säule sieht und alle anderen von dieser verdeckt
sind. Diese Nachteile könnten z.B. dadurch überwunden werden,
dass jedes Element der Matrix statt eines einzigen Wertes eine Liste
beliebig vieler Z-Werte speichert. Um den Speicherbedarf und
Rechenaufwand möglichst klein zu halten würde man hier
zweckmäßiger Weise nur solche Werte abspeichern, die an der
Obefläche eines Objekts liegen. Außerdem könnte es
sinnvoll sein die Z-Werte einer solchen Liste zu sortieren (von "vorne"
nach "hinten", oder umgekehrt). Diese Erweiterung hat - trotz
möglicher Optimierungen - den Nachteil den Speicherbedarf sowie
den Rechenaufwand enorm in die Höhe zu treiben.
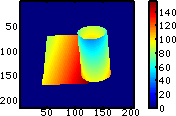 |
Z-Buffer:
Z-Werte
(Entfernung) für alle Pixel (hellblaue Pixel sind nah, rote Pixel
weit
entfernt, dunkelblaue Pixel sind "leer")
|
- Die zweite Matrix nenne ich im
Folgenden Normalenmatrix -
sie enthält für jeden
Bildpunkt einen Normalenvektor, der die Orientierung der
Oberfläche an diesem Punkt angibt. Dieser Wert kann auch aus dem
Z-Buffer ermittelt (geschätzt) werden, indem die umliegenden
Punkte berücksichtigt werden. Dies ist z.B. bei Fraktalen
nötig, bei denen man tatsächlich nur eine Menge von
Raumpixeln ermittelt (also die Punkte im Raum, die zum Fraktal
gehören). Diese Schätzung ist aber insbesondere in den
Bereichen scharfer Kanten problematisch. Berechnet man den Z-Buffer
z.B. für ein
Objekt, welches durch Bezier-Flächen beschrieben ist, kann man die
Normalenvektoren besser und präziser direkt aus den
Bezier-Flächen
ermitteln.
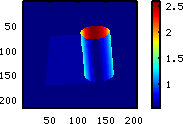 |
| Winkel der
Normalenvektoren zur Blickrichtung (Flächen die senkrecht zur
Blickrichtung stehen sind dunkelblau oder dunkelrot, Flächen die
längs zur Blickrichtung liegen sind gelb, grün bis
türkis) |
Benötigt werden diese Normalenvektoren sowohl für die
Berechnung von Spiegelungen, als auch für die Berechnung des
Lichtanteils, der in Richtung des Betrachters reflektiert wird. Das
unten dargestellte Schema zeigt den Zusammenhang: je nachdem wie die
Oberfläche ausgerichtet ist, erscheinen die Bereiche heller oder
dunkler.
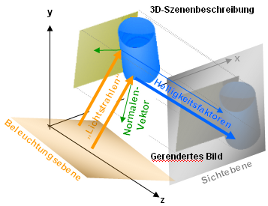 |
|
Helligkeitsfaktoren
aufgrund
von
Reflektionen
(Licht, das abhängig von der
Ausrichtung der Oberfläche mehr oder weniger stark in Richtung
Beobachter "reflektiert" wird)
|
- Die dritte Matrix ist die Farbmatrix - sie gibt für
jeden Punkt die Farbe
des Objekts an. Damit ist die
Farbmatrix praktisch bereits das spätere Bild, es fehlen "nur" noch die
Helligkeitsänderungen (Schatten, Reflektionen), die durch den
Rendering-Algorithmus zunächst berechnet und die Farben dann damit
angepasst werden. Die Farbe kann auch aus der eigentlichen
Objektfarbe
sowie Spiegelungen erzeugt worden sein. Ist ein Pixel übrigens vollkommen transparent, so
sollte es wie ein nicht vorhandenes Pixel behandelt
werden und in keiner der Matritzen auftauchen. Halbtransparente Pixel
sind zwar nicht prinzipiell verboten, da es aber unmöglich ist
mehrere Ebenen im Z-Buffer abzubilden (nur genau ein Z-Wert für
jedes Element des Z-Buffers ist möglich) wird hinter einem solchen
halbdurchsichtigen
Pixel trotzdem nichts anderes durchscheinen (es gibt eben kein
"Dahinter").
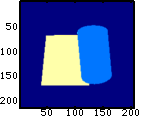 |
Die Farbmatrix
entspricht bereits dem Bild ohne Helligkeitsänderungen durch den
Renderer
|
- Die vierte (optionale)
Matrix ist die Material-Matrix,
die
für
jeden
Punkt
je
einen
Wert
für
den
Glanz
und
für
die
Spiegelungsfähigkeit
enthält.
Ist
die Matrix nicht
gegeben, bzw. für einen Punkt kein "Matrial" angegeben wird ein
globaler Default-Wert angenommen. Daher erfolgt eine genauere
Beschreibung im nächsten Abschnitt. Das "Material" könnte
auch den Farbwert beinhalten. Da bei mir aber oft jeder Punkt eine
andere Farbe hat, aber zumeist alle Punkte die gleichen
Materialeigenschaften
besitzen habe ich mich dafür entschieden Material und Farbe
vollkommen unabhängig voneinander zu halten.
Weitere Parameter sind "global"
für die ganze
Szene bzw. das ganze Bild festgelegt und werden im nächsten
Abschnitt erläutert.
Globale
Parameter
Die folgenden "globalen" Parameter gelten für alle Bildpunkte
(sofern diese nicht z.B. durch spezielle Material-Eigenschaften, die in
der Material-Matrix für eine Punkt
definiert sind überschrieben werden):
- Grund-Licht:
Beschreibt die Stärke des Lichts,
welches nur von der Entfernung zur Lichtquelle (besser) Lichtebene
abhängt (die Normalenvektoren werden hier nicht verwendet). Dies
war im allerersten Ansatz das einzige Licht (welches damals auch nur
direkt von vorne kam). Man erhält damit aber nur einen sehr, sehr
diffusen Eindruck von der räumlichen Gestalt.
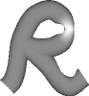 |
|
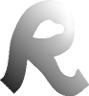 |
Nur
Grund-Licht
direkt von vorne
|
|
Nur
Grund-Licht
von rechts oben
|
- Reflektion und Glanz:
Geben die
Stäke der
Reflektion an, die von der Richtung des Lichts bezogen zur
Blickrichtung unter Berücksichtigung des Normalenvektors an einem
bestimmten Punkt abhängt. Dabei gibt der Reflektions-Wert den
Anteil des
Lichts an der "reflektiert" wird und der Glanz-Wert bestimmt wie stark
das reflektierte
Licht von den Winkeln (Blickwinkel, Lichteinfallswinkel und
Normalenvektor) abhängt (beide Werte müssen größer
Null sein, damit eine Reflektion überhaupt stattfindet).
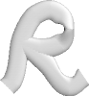 |
|
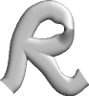 |
|
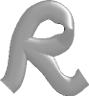 |
|
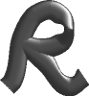 |
Mittlere
Reflektions-
(0.5) und Glanz-Werte (2.0)
|
|
Hoher
Reflektions-Wert
(0.9), mittlerer Glanz-Wert (2.0)
|
|
Mittlerer
Reflektions-
(0.5), hoher Glanz-Wert (10.0)
|
|
Hohe
Reflektions-
(0.9) und Glanz-Werte (10.0) |
- Minimum-Licht:
Minimale Helligkeit für alle (nicht
leeren) Bereiche.
- Diffusionsabstand:
Gibt an über welche Entfernung Licht
"diffus" auch auf umliegende Pixel wirkt. Ist dieser Wert zu gering
sieht man Kanten, die dadurch entstehen, dass es ja nur endlich viele
Bildpunkte (Breite x Höhe) gibt und dadurch "Stufen" in der
Obefläche des Objekts entstehen, die dann, je nach
Lichteinfallswinkel, Schatten auf benachbarte Bildpunkte werfen
können (siehe auch hier) -
ein Problem, an das ich zunächst garnicht gedacht
hatte und das mich dann fast zur Verzweiflung getrieben hat :-) Welcher
Wert zu gering bzw. hoch genug ist, hängt nicht (stark) vom
konkreten Objekt ab. Ein Wert von 10 hat sich im Allgemeinen als
ausreichend erwiesen.
 |
Zu geringe
"Diffusion"
|
- Materialstärke:
Beschreibt eine angenommene Dicke der
Oberfläche in
Z-Richtung (Tiefe). Dieser Wert ist insbesondere für den
Schattenwurf von Bedeutung. Nimmt man an, dass die im Z-Buffer
repräsentierte Oberfläche unendlich dünn ist, kann es
wegen der begrenzten Auflösung in Bildpunkten zum Durchscheinen
des Lichts zwischen den Bildpunkten kommen. Das führt dann dazu,
dass Schatten von kleinen hellen Punkten unterbrochen sind (was sehr
störend ist).
- Hintergrundfarbe:
Die Farbe, die für Bildpunkte gewählt wird, die "leer" sind.
Sofern das Ausgabeformat Transparenzen unterstützt, kann hier auch
mit einer duchsichtigen oder teildurchsichtigen Farbe gearbeitet werden.
- Mirror:
Stärke mit der Spiegelungen wirken
(gespiegelt werden können z.B. Bilder, die sich auf den sechs
Seiten einer virtuell die Szene umgebenden Box befinden, siehe auch das
Beispiel oben). Diese
Art der Spiegelung ist bei mir eine Vorverarbeitung der die Farbe der
Bildpunkte (Farb-Matrix) manipuliert und damit nicht Teil des
eigentlichen Rendering-Algorithmus' ist.
- Schärfeebene:
Eine Z-Koordinate für die Ebene in der Punkte scharf abgebildet
werden.
- Maximaler Blur-Radius:
Maximaler Radius für den Gausschen Weichzeichner, der auf Punkte
angewendet wird, die einen maximalen Abstand zur Schärfeebene
haben. Ist dieser Abstand 0 wird keine Tiefen-(Un-)Schärfe
berechnet.
- Blauverschiebung:
Ein Faktor der angibt wie stark die weitest entfernten Punkte ins
Bläuliche verschoben werden
- Dunst (Weißverschiebung)
Ein Faktor der angibt wie stark die weitest entfernten Punkte
aufgehellt werden sollen.
Vorverarbeitung
- Perspektivische
Verzerrung:
Der Algorithmus ist
prinzipiell für parallelperspektivische Darstellungen konzipiert.
Um dennoch eine natürlichere Fluchtpunktperspektive zu erzeugen,
wird ein Trick eingesetzt: Die Eingangs-Matritzen (siehe oben) für den Algorithmus (siehe unten) werden für ein entsprechend
verzerrtes Objekt erzeugt (ich benutze dafür, wie auch für
Rotationen und Translationen sogenannte "Transformationen", die
gegebene X-,
Y- und Z-Werte in entsprechend transformierte Koordinaten umrechnen).
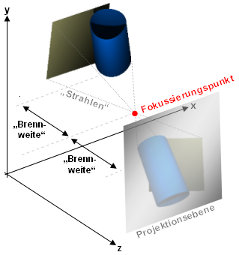
Für die perspektivische Verzerrung wird die " Linsentransformation" benutzt. Diese
macht Folgendes:
Es wird ein Fokussierungspunkt
gewählt, der (in Z-Richtung) vor der abzubildenden Szene liegt,
wobei der Abstand in Z-Richtung (die " Brennweite")
das
Maß
der
Verzerrung
(Weitwinkel-/Teleoptik)
bestimmt.
Um
die
Größenverhältnisse
in
etwa
beizubehalten
wird
ungefähr
in
derselben
Entfernung
dahinter
eine
Projektionsfläche
"aufgespannt"
(rein virtuell natürlich). Jetzt wird für jeden Punkt
berechnet, wo auf der Projektionsfläche ein Strahl, der von diesem
Punkt durch den Fokussierungspunkt geht, aufträfe. Von diesem Projektionspunkt werden die X- und
Y-Koordinate für den zu transformierenden Punkt übernommen
(die Z-Koordinate bleibt dagegen erhalten, da sonst ja alle diegleiche
Z-Koordinate hätten - nämlich die der
Projektionsfläche). Da das Objekt dabei auch noch um 180°
gedreht wird (oben/unten und rechts/links werden vertauscht), sollten
X- und Y-Koordinate zusätzlich negiert werden, damit die Szene
wieder richtig herum erscheint.
 |
|
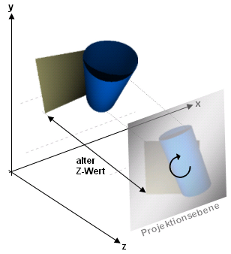 |
"Linsentransformation": Die
Szene wird durch einen Fokussierungspunkt auf eine Projektionsebene
projeziert (die Szene erscheint um 180° gedreht und ist
perspektivisch verzerrt)
|
|
Die
verzerrten
Objekte
entstehen
indem
die
X-
und
Y-Koordinaten
der
Projektion
negiert
werden
(Drehung
um
180°)
und
die
alte
Z-Koordinate
wieder
hergestellt
wird
|
Dass diese "Fluchtpunktperspektive" nicht wirklich korrekt ist merkt
man
insbesondere an diesen Dingen:
- Der Schattenwurf
ist nicht korrekt, denn durch die
Verzerrung des Objekts selbst sehen weiter hinten liegende Teile ja
nicht nur kleiner aus, sondern sind tatsächlich kleiner und werfen
entsprechend kleinere Schatten. Zudem verändern sich auch die
Winkel. Im Beispiel oben kann man
schön erkennen, dass der Schatten im perspektivisch verzerrten
Bild eine andere Ausdehnung hat, obwohl der Lichteinfallswinkel
für beide Bilder gleich gewählt wurde.
- Die Reflektionen
sind nicht physikalisch korrekt, weil auch die Normalenvektoren, also
die
Ausrichtung der Oberflächen durch die Transformation verzerrt
werden.
- Entsprechend werden auch die Spiegelungen (siehe
auch nächsten Punkt) nicht physikalisch korrekt berechnet.
In der Praxis fallen diese
Ungenauigkeiten, bei den von mir erzeugten Bildern aber kaum auf (der
Schattenwurf ist ja ohnehin nicht korrekt, da nur sichtbare Teile
berücksichtigt werden; ebenso sind die Spiegelungen nicht korrekt,
weil Objekte sich nicht gegenseitig spiegeln können) - im
Gegenteil, die räumliche Wirkung der Bilder ist oft besser.
Würde man erst das gesamte Rendering auf einem unverzerrten Objekt
machen und erst danach eine Verzerrung der Bildpunkte durchführen,
könnte man Probleme mit der Auflösung bekommen, denn
näher am betrachter liegende Teile werden ja dabei eher
größer. Man müsste also zusätzliche Pixel
interpolieren um "Löcher" im Objekt zu vermeiden. Das sähe
dann aber ähnlich (schlecht) aus, wie wenn man ein normales
pixelbasiertes (2D)
Bild vergrößert. Hier rächt sich etwas, dass der
Algorithmus letztlich auf (Raum-)Pixeln arbeitet und nicht auf beliebig
skalierbaren Flächen (z.B. Dreiecksflächen).
Das meiste dazu ist oben
schon gesagt worden, trotzdem hier nochmal etwas ausführlicher:
Für jeden Punkt
wird abhängig vom Normalenvektor an dieser Stelle berechnet
welcher Punkt eines oder mehrerer Bilder (die z.B. in der Form einer,
die Szene umgebenden Box, angeordnet sind - siehe Beispiel) gespiegelt werden soll. Die
Farbe dieses zu spiegelnden Punktes wird mit der Orignal-Farbe des
Objektpunktes verrechnet und ergibt die neue Farbe, die in die Farb-Matrix eingetragen und dem Rendering-Algorithmus übergeben wird.
Ähnlich wie oben, bei der perspektivischen Verzerrung beschrieben,
werden Schnittpunkte von "Sichtstrahlen", mit einem "Spiegelobjekt"
berechnet. Das "Spiegelobjekt" enthält dabei die zu spiegelnden
Bilder und hat z.B. die Form einer sechsseitigen Box. Ein "Sichtstrahl"
läuft nun vom Auge (der Sichtebene) zu einem Punkt auf der
Oberfläche eines Objekts und von dort, abhängig vom
Auftreffwinkel und Normalenvektor der Oberfläche an diesem Punkt
weiter zu dem "Spiegelobjekt".
 |
(das Bild auf der Sichtebene entsteht erst
später, die Farbe des
gespiegelten Punkts wird zunächst dem spiegelnden Punkt zugewiesen)
|
Der
Algorithmus im Detail
Das Objekt / die Szene wird beschrieben durch folgende Eingangswerte:
Um die Beschreibung des Algorithmus' möglichst kompakt zu halten,
werden hier vorab ganz kurz zentrale Zwischenergebnisse
veranschaulicht (die Details der Berechnung finden sich dann unten):
- Das zentrale Zwischenergebnis des Algorithmus sind
die Helligkeitsfaktoren
(Matrix), mit denen dann die Farbwerte der
Farbmatrix angepasst werden.
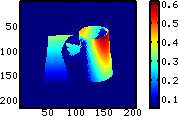 |
|
Matrix der
Helligkeitsfaktoren helle Bereiche erscheinen rot, dunkle Bereiche blau
(Licht kommt von rechts oben)
|
- Ebenfalls an etlichen Stellen verwendet wird die
"Projektionsfläche". Dies
ist eine weitere Matrix, die aber eine
anderer
Größe hat, als alle anderen bisher erwhänten Matritzen.
Sie enthält eine
Art Z-Buffer, der aus dem Originalen Z-Buffer entsteht indem die Pixel
in Richtung des Lichts gedreht werden - also einen Z-Buffer für
die Licht- statt der Sichtebene (Genaueres siehe unten).
Unten sind zwei Beispiele für unterschiedliche Lichteinfallswinkel
zu sehen.
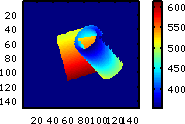 |
|
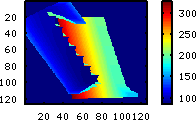 |
|
Matrix der, in Richtung des
Lichts, gedrehten Pixel (hier ist zu erkennen, dass der Zylinder keine
Rückseite hat, was zu dem Fehler beim Schattenwurf führt)
|
|
Hier die
Matrix, für den Fall, dass das Licht genau von rechts kommt.
Dadurch ist noch deutlicher zu erkennen, dass der Zylinder keine
Rückseite hat
|
Die folgende Grafik zeigt für eine Zeile von 5 Bildpunkten des
Z-Buffers und einen bestimmten Lichteinfallswinkel die resultierende
"Projektionsfläche". Zu sehen ist u.a., dass nicht alle Pixel des
Z-Buffers aus der Richtung des Lichts zu "sehen" sind. Diese Pixel
liegen daher im Schatten.
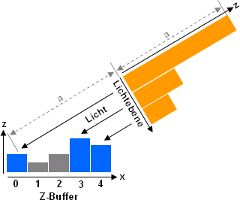 |
|
Projektion
des
Z-Buffers
in
Richtung
des
Lichts.
Graue
Pixel
sind
aus
Richtung
des
Lichts
nicht
zu
sehen
und
liegen
daher
im
Schatten.
|
Die Auflösung der Projektionsebene sollte ggf. außerdem an
den Lichteinfallswinkel angepasst werden
- d.h. die Matrixelemente bzw. "Pixel" der Projektionsebene können
in
X- und Y-Richtung virtuell kleiner oder größer sein als im
Z-Buffer. Diese
Anpassung erfolgt zweckmäßiger Weise so, dass ein Pixel des
Z-Buffers
etwa einem Pixel in der Projektionsebene entspricht.
Ablauf:
- Initialisierung:
Die Matrix, die für jeden
Bildpunkt den Helligkeitsfaktor enthält,
wird
angelegt.
Dies
ist
das
entscheidende
Zwischenergebnis
des
gesamten
Algorithmus'.
Initial
sind
alle
Werte
dieser
Matrix
leer
(z.B.
"null",
aber
nicht
"0").
Am
Ende
werden
mit
diesen
Faktoren
schließlich
die
Helligkeitswerte
jedes
Farb-Pixels
(siehe
Farb-Matrix) angepasst.
Außerdem wird die "Projektionsfläche"
initialisiert.
Dabei
handelt
es
sich,
wie
schon
beschrieben,
um
eine
weitere
interne
Matrix,
die
die
Raumpixel
des
Z-Buffers
aufnimmt,
nachdem
sie in Richtung des
Lichts gedreht wurden (aus den Koordinaten (x,y,z)
werden durch diese Projektion die Koordinaten (xr,yr,zr)).
Die
Projektionsfläche
hat
damit
i.d.R.
eine
andere
Größe
als
alle
zuvor
genannten
Matritzen!
Prinzipiell
enthält
jedes
durch
Drehung
des
Ursprungspixels
entstandene
Raumpixel
der
Projektionsfläche
den
Abstand
zum
Licht
(genauer
der
Lichtebene)3).
Damit
ist
die
Projektionsfläche
auch
eine
Art
Z-Buffer.
Allerdings
enthält
sie
zweckmäßiger
Weise
für
jedes
ihrer
Raumpixel
auch
einen
Rückverweis
auf
die
X-
und
Y-Koordinaten
des
originalen
Pixel
des
Z-Buffers,
sowie
der
Normalen-
und
der
Farb-Matrix4).
Es hat
sich zudem gezeigt, dass es für den Schattenwurf notwendig ist,
dass man
nicht nur die direkt im Z-Buffer repräsentierten Punkte auf diese
Projektionsfläche projeziert, sondern für jeden Punkt auch
eine Anzahl (unsichtbarer) Punkte die virtuell dahinterliegen. Auf der
Projektionsfläche sind diese zusätzlichen Punkte dann u.U.
nicht mehr durch den ersten, oder einen
anderen Punkt verdeckt und tragen somit zum Schattenwurf bei.
Zur Bestimmung der Anzahl dieser zusätzlichen Punkte wird die
"Materialdicke" herangezogen (siehe oben).
Die Materialdicke gibt dabei direkt die Anzahl der Raumpixel in der
Tiefe vor.
- Berechnung des
direkten Lichts:
Jeder Raumpixel des Z-Buffers, der durch ein
Raumpixel auf der Projektionsfläche repräsentiert ist bekommt
den Helligkeitsfaktor 1. Für alle anderen Raumpixel des Z-Buffers
ist damit klar, dass sie nicht direkt vom Licht angestrahlt sind, da
sie durch andere Raumpixel
"abgeschattet" werden (diese abgeschatteten Raumpixel werden in diesem
Schritt nicht verändert haben damit weiterhin keinen
Helligkeitsfaktor).
- Diffuses Licht
berechnen:
Für jedes Raumpixel, das nicht direkt
angestrahlt ist (also bisher noch keinen Helligkeitsfaktor zugewiesen
bekommen hat), wird der direkt angestrahlte Punkt gesucht der dieses
Raumpixel "abschattet". Das ist genau jenes Raumpixel, welches auf der
Projektionsfläche an genau derselben Stelle repräsentiert
ist, an der auch das abgeschattete Pixel (nach Drehung in Richtung des
Lichts) liegen würde. Zwischen diesen beiden Pixeln wird der
Abstand a
berechnet. Der Helligkeitsfaktor des abgeschatteten Pixels ergibt sich
dann durch:
HelligkeitsFaktor(x,y)
=
max(0,
1
-
(a2 /
DiffusionsAbstand2)),
wobei der oben bereits erläuterte
"Diffusionsabstand" benutzt wird. Diese Formel ist übrigens, wie
die folgenden auch, nirgendwo in Stein
gemeißelt und könnte auch anders gewählt werden...
- Reflektiertes Licht
berechnen:
Für jeden direkt beleuchteten Punkt (also alle Punkte
die auf der Projektionsfläche repräsentiert sind), wird der
Winkel berechnet, mit dem ein Lichtstrahl, der ausgehend von der
Lichtquelle von diesem Punkt relektiert wird auf die Sichtebene trifft.
Die Reflektionsrichtung ist dabei abhängig vom Normalenvektor an
diesem Punkt5)
("Einfallswinkel = Ausfallswinkel")6). Die so berechneten
Winkel für alle Punkte werden bei mir in einer weiteren Matrix
(der Winkel-Matrix) mit
derselben Größe wie die Projektionsfläche
zwischengespeichert.
Danach wird für jeden Helligkeitsfaktor, unter
Berücksichtigung der Werte für Reflektion
und
Glanz, folgende Anpassung
vorgenommen:
HelligkeitsFaktor(x,y)'
=
HelligkeitsFaktor(x,y)
*
((1.0
-
Reflektion)
+
normGauss(angle,
pi/2.0,
1.0/Glanz)
*
Reflektion)
Wobei für jeden Punkt (x,y)
jeweils der Winkeln (angle)
genommen
wird
der
in
der
Winkel-Matrix
an
der
Position
(xr,yr) des in Richtung des Lichts
gedrehten Originalpixels (aus dem Z-Buffer) zu finden ist (die
Winkel-Matrix wird nur für diesen einen Berechnungsschritt
benötigt). Die Funktion normGauss ist die Gauss-Funktion, so
normiert, dass an der Stelle x = mean der Wert 1 herauskommt, wodurch
sich die normale Gaussfunktion vereinfacht zu:
normGauss = exp(-(x-mean)2 /
(2*var))
- Grund-Licht
berechnen:
Die Helligkeitsfaktoren aller Pixel werden mit
folgender Formel angepasst:
HelligkeitsFaktor(x,y)'
=
(1.0
-
GrundLicht)
*
(l
*
HelligkeitsFaktor(x,y))
+ GrundLicht * l,
wobei gilt:
l
= 1.0 - (zr - minZ) / Range,
es gilt zudem:
- zr
ist die Z-Koordinate des in Richtung des Lichts gedrehten Pixels,
- minZ
ist der minimal mögliche Wert für zr
(Punkte mit diesem oder einem kleineren Abstand zum Licht erhalten das
maximale Grund-Licht, welches durch den Parameter GrundLicht
bestimmt ist)
- Range
ist die Differenz zwischen dem minimalen und dem maximalen Wert
für zr
(Punkte mit dem Abstand minZ+Range
und mehr zum Licht erhalten das minimale Grund-Licht - also garkeins)
Range
und minZ
können dabei entweder automatisch aus den Werten der
Projektionsfläche ermittelt werden oder aber anderweitig
vorgegeben werden (z.B. indem diese Werte als Zusatzattribute des
Z-Buffer abgelegt wurden).
- Minimal-Licht
berechnen:
Die Helligkeitsfaktoren aller Pixel werden so angepasst, dass sie
mindestens den vorgegebenen Minimalwert haben (siehe oben). Dazu wird einfach folgende lineare
Transformation benutzt:
HelligkeitsFaktor(x,y)'
=
HelligkeitsFaktor(x,y)
*
(1.0
-
minLight))
+
minLight
- Bild erzeugen:
Ein Bild wird angelegt, das dieselbe Höhe und Breite hat wie auch
der Z-Buffers, die Normalenmatrix und die Farb-Matrix. Jedes Pixel
bekommt die Farbe die durch das entsprechende Element der Farbmatrix
vorgegeben ist, wobei diese Farbe zuvor noch mit dem entsprechenden
Helligkeitsfaktor manipuliert wird. Dabei ergibt sich z.B. der neue
Wert für den Grün-Kanal eines Pixels durch:
green(x,y)'
=
min(255,
max(0,
green(x,y)
*
HelligkeitsFakor)),
wobei die Werte eines Farbkanals hier im Bereich 0 bis 255 liegen
können. Für die Kanäle Rot und Blau gilt entsprechendes.
Das Bild
kann dann z.B. in einem gängigen Grafik-Format gespeichert werden
- wobei auch ich dafür dann eine der bekannten Libraries nutzen
würde :-)
Nachbearbeitung
Zusätzlich sind einige Nachbearbeitungsschritte (bei mir intern
als "Filter" bezeichnet) möglich. Diese benötigen zumeist nur
das gerenderte Bild - können aber auch den Z-Buffer verwenden,
wenn zusätzlich die Z-Koordinate benötigt wird. Die Filter
werden normalerweise in der hier angegebenen Reihenfolge auf das Bild
angewendet (mögliche Abweichungen von dieser Reihenfolge sind
jeweils angegeben):
- Hue-,
Saturation-
und
Brightness-Anpassung:
Durch eine entsprechende Farbraumkonvertierung werden alle Pixel-Farben
angepasst. Dies erfolgt vor den folgenden Schritten, damit nur die
eigentlichen Objektpixel verändert werden, der Hintergrund aber
unverändert bleibt (hätte man aber auch anders machen
können).
- Blauverschiebung und Dunst:
Abhängig von der Tiefe eines Punktes und den Einstellungen werden
die Farben aufgehellt und ins Bläuliche verschoben.
- Setzen
eines
Hintergrundbildes:
Optional werden alle (semi-)transparenten Pixel mit der Farbe des
entsprechenden Pixels eines (ggf. skalierten und verschobenen)
Hintergrundbildes verrechnet (dieses kann selbst wieder transparente
Pixel enthalten, so dass der nächste Schritt auch dann noch Sinn
macht).
- Setzen
einer
Hintergrundfarbe:
Alle (immernoch) (semi-)transparenten Pixel können mit eine
Hintergrundfarbe verrechnet werden (unter dem Punkt "Tiefenschärfe berechnen" ist ein Beispiel zu sehen, in dem ein
Schachbrettmuster als Hintergrundbild verwendet wurde). Optional können sowohl
Hintergrundfarbe als auch Hintergrundbild bereits als erste Filter
angewendet werden, so dass sich alle Filter und nicht nur die
Tiefenschärfeberechnung auch auf den Hintergrund auswirken.
- Tiefenschärfe
berechnen:
Die
Berechnung der Tiefenschärfe benötigt nur das zuvor angelegte
Bild,
sowie den Z-Buffer (für jeden Punkt wird
neben der X- und
Y-Koordinate
auch die Z-Koordinate zur Ermittlung des Abstands von der Schärfeebene
benötigt). Daher ist dieser Schritt intern als eine
Nachbearbeitung
implementiert. Prinzipiell wird für jeden Punkt ein
Weichzeichnungs-Radius bestimmt, der umso größer ist je
weiter der Punkt von der Schärfeebene entfernt ist. Statt eines
linearen Zusammenhangs zwischen diesem Radius und dem Abstand zur Schärfeebene wird
eine (re-normierte) Arcustangens-Funktion
verwendet. Der Radius für den Punkt an Position (x,y) ergibt sich
damit durch:
Radius(x,y)
=
atan(abs(z-Schärfeebene)/maxDist
*
4)
/
atan(4)
*
MaxBlurRadius)
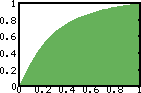 |
Verwendeter
Ausschnitt der Arcustangens-Funktion (mit max. Distanz = 1 und max.
Blur-Radius = 1)
|
Die Normierung auf den Wert von atan(4) ist dabei eine reine
Konvention, damit der maximale Blur-Radius
auch tatsächlich, für die Punkte erreicht wird, die am
weitesten von der Schärfeebene
entfernt sind. Um Probleme, die durch den Wert 0 für den Radius
auftreten können zu vermeiden, ist es sinnvoll diesen Wert noch +1
zu nehmen. Dadurch ergibt sich insbesondere auch ein schönerer
Übergang zwischen ganz scharfen und leicht unscharfen Bereichen
(diese Optimierung ist in den unten gezeigten Beispielen übrigens
noch nicht enthalten, was man jeweils an der linken vorderen Ecke des
Rechtecks erkennen kann).
Mit dem so berechneten Radius7)
wird ein Gausscher Weichzeichner auf den Punkt (x,y) angwendet. Dabei
wird
der Wert jedes Farbkanals (z.B. Rot, Grün, Blau und ggf. Alpha)
auf die umliegenden Punkte, mittels einer Gewichtungsfunktion,
verteilt (die Punkte in der Mitte bekommen den größten
Anteil, die Punkte weiter außen bekommen abhängig vom Radius
immer weniger ab). Als Gewichtungsfunktion wird eine zweidimensionale
Normalverteilung verwendet:
|
1 |
|
-
|
dx2+dy2
2
var(x,y) |
Gewicht(x+dx,y+dy)
=
|
|
e
|
|
|
|
2
*
PI
*
var(x,y) |
|
|
|
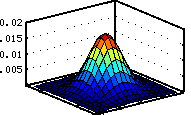 |
Gewichtsfunktion
(2D-Normalverteilung)
bei
Radius
=
9
(im
Intervall
x
=
[-9...+9],
y
=
[-9...+9])
und
Varianz
=
(9/3)2 = 9
|
wobei die Varianz var(x,y)
=
(Radius(x,y)/3)2
gewählt wird, so dass nur Bereiche der Funktion mit sehr kleinen
Werten (Gewichten) außerhalb des Radius liegen, die wegen ihrer
Kleinheit aber gefahrlos abgeschnitten werden können, ohne dass
dies sichtbare Auswirkungen hätte. Die Variablen dx und dy iterieren jeweils
über das Intervall [-Radius(x,y)...+Radius(x,y)].
Hier
ist
wichtig,
dass
der
Radius
nie
Null
ist,
da
die
Funktion
für
var
=
0 nicht definiert ist. Da gerade diese Funktion sehr oft
ausgewertet werden muss und dabei recht langsam ist, verwende ich
mittlerweile Look-Up-Tables, in denen die Werte für (ganzahlig
gerundete) Radien, sowie quadrierte Abstände vom Zentrum (dx2+dy2)
abgelegt
sind.
Wie sich gezeigt hat, birgt dieses Verfahren noch ein paar Fallen.
Es reicht leider nicht, einfach, wie beschrieben, einen Gausschen
Weichzeichner, der für jeden
Punkt, abhängig von dessen Abstand zur Schärfeebene,
einen anderen Radius verwendet zu nehmen8),
weil
dann
an
Übergängen
zwischen
scharfen
Objektteilen
zu
sehr
unscharfen
Teilen
Helligkeitsartefakte
auftreten.
Das
kommt
daher,
dass
Punkte die sehr
unscharf sind viel ihrer Helligkeit an umliegende Punkte abgeben,
während schärfere Punkte ihre Helligkeit in einem engeren
Bereich konzentrieren. An Übergängen zwischen mehr und
weniger scharfen Bereichen entsteht so ein Ungleichgewicht, welches
sich in hellen und dunklen "Auren" äußert. Der Effekt ist
unten im linken Bild zu erkennen. Hier hilft es für jeden
Punkt die Summe aller Gewichte, die für diesen Punkt zur Anwendung
kommen, zu summieren (also auch die für die Weichzeichnung von
Punkten in der Umgebung, die auf den fraglichen Punkt "ausstrahlen").
Die Helligkeit jedes Punktes (also alle Farbkanäle) wird danach
mit dieser Gewichtssumme normiert. Dies erfordert leider, dass man eine
weitere Matrix anlegt in der die Gewichte für jeden Punkt
gesammelt, d.h. aufsummiert werden.
 |
|
 |
|
 |
|
 |
Ohne
Normierung der Gesamtgewichte (und ohne Gauss-Adaption): helle und
dunkle "Auren" zeigen sich
|
|
Ohne
Gewichts-Adaption: schärfere Bereiche werden in Randzonen vom
Hintergrund (zu stark) überstrahlt
|
|
Mit Normierung
der Gesamtgewichte und
Gewichts-Adaption:
schön erkennbarer Verlauf der Tiefenschärfe
|
|
Kein negativer
Einfluss auf den Hintergrund (gleichbleibend unscharf, auch an den
Objekträndern) |
Aber selbst dann bleibt noch ein weiteres Problem: Punkte die sehr
unscharf sind strahlen auch auf scharfe Punkte in ihrer Nähe aus
und überstrahlen diese dadurch teilweise recht stark. Dies ist
oben im zweiten Bild zu erkennen. Die Objektränder scheinen, trotz
ihres unterschiedlichen Abstands, fast gleichmäßig unscharf
zu sein. Diese Unschärfe kommt aber hauptsächlich durch die
Überstrahlung durch den durchweg maximal unscharfen Hintergrund
(das Problem wird dadurch verstärkt, dass der Hintergrund sehr
hell ist). Um dieses
Problem etwas abzumildern verwende ich folgenden Trick: die
Gaussfunktion wird mit einem Faktor multipliziert, so dass breitere
Verteilungen noch weiter
abgeflacht werden, was zur Folge hat, dass schärfere Punkte
weniger überstrahlt werden können:
Adaptiertes_Gewicht(x,y)
=
Gewicht(x,y)
*
sqrt(Gewicht(0,0)
Also Normierungsfaktor dient der Maximalwert der Gewichtsfunktion, der
ja an der Stelle (0,0) auftritt. Die Verwendung der Wurzel dieses
Wertes mildert das ganze nur wieder etwas ab. Andere Ideen (z.B.
Adaption der Gewichte je nachdem wie die Werte in der Nachbarschaft
sind) hatten teilweise zur Folge, dass in der Umgebung scharfer
Objekteile z.B. auch der Hintergrund schärfer wurde. Dies ist bei
dem oben beschriebenen Verfahren, wie man im rechten Beispiel sieht,
nicht der Fall.
Beide Workarounds entbehren sicherlich weitgehend jeder physikalischen
Grundlage, ergeben aber recht ansehnliche Resultate...
Anwendungen
Die 3D-Fraktale zu deren Visualisierung
der Algorithmus ursprünglich entstanden ist sind hier näher beschrieben.
Später habe ich dann auch noch Objekte aus Bezier-Flächen
damit gerendert, wie hier
beschrieben ist (einige der erzeugten Bilder sind auf den Seiten auch
zu sehen). Programme (3D-Fraktal-Generator,
Bezier-Flächen-Programm,
3D-Text-Erzeugungsprogramm),
die
den hier beschriebenen Renderer
benutzen sind hier zum Download
bereitgestellt.
1)
|
Übrigens werden die Lichtstrahlen
dabei in der umgekehrten Richtung "verfolgt", was den großen
Vorteil hat, dass man nur die Lichtstrahlen tatsächlich berechnet,
die wirklich das "Auge" erreichen. |
2)
|
Für die
Erklärung ist es einfacher von drei Matritzen zu sprechen;
softwaretechnisch kann alles in einer Matrix enthalten sein, bei der
jedes Element die drei Anteile Z-Koordinate, Normalenvektor und Farbe
für diesen Punkt hat (evtl. plus weiterer Attribute). |
3)
|
Da auch die
Projektionsfläche eine Matrix ist, müssen die Koordinaten xr
und yr entsprechend ganzahlig gerundet werden, um das Element der
Projektionsfläche zu finden, welches zu diesen Koordinaten den
Z-Wert (plus weiterer Daten) enthält.
|
4)
|
Wie jeder
Z-Buffer enthält auch die Projektionsfläche immer nur die
Pixel die den kleinsten Abstand zum Betrachter bzw. hier dem Licht
haben - es ist also i.d.R. nicht jedes Raumpixel des Z-Buffers auch
durch ein Pixel auf der Projektionsfläche repräsentiert, da
mehrere
Z-Buffer-Elemente auf denselben Punkt der Projektionsfläche
"fallen"
können. |
5)
|
Hier kann man
den Rückverweis von den gedrehten Raumpixeln der
Projektionsfläche auf die Originalkoordinaten gut gebrauchen. |
6)
|
Die Richtung
des an einem Punkt reflektierten Lichtstrahls kann dabei mit Hilfe von
Ebenen und Linien, sowie den Schnittpunkten ermittelt werden.
|
7)
|
Es wird dabei
einfach ein rechteckiger Bereich von xi = [x-radius...x+radius] und yi
= [y-radius...y+radius] abgearbeitet. Die Bezeichnung "Radius" ist also
etwas irreführend. Die "Rundheit" der Unschärfe kommt allein
durch die Form der zweidimensionalen Normalverteilung zur Gewichtung.
|
8)
|
Wobei eine
Normierung der Summe
aller Gewichte des Gausschen Weichzeichners für einen Punkt auf 1
voraussgesetzt wird.
|
|

 .
.